GEO Audit
Deep Dive GEO Audit:
Finde heraus, warum KI deine Wettbewerber nennt
Wir messen deine AI-Visibility in kaufnahen Prompt-Clustern (Best/Compare/Alternatives), analysieren Quellen und Entity-Signale und liefern eine priorisierte Roadmap, die messbar SoA, SoC, SoM und Sentiment verbessert.
In Large Language Modellen (LLMs) entscheiden Entitäten und Quellenlage, ob du empfohlen oder ignoriert wirst. Wenn eindeutige Signale fehlen, wirst du übergangen, selbst wenn dein Marketing Nachfrage erzeugt.
Pipeline Qualität sinkt, weil du in Shortlists nicht vorkommst
CAC steigt, weil du Sichtbarkeit einkaufen musst, die du organisch verlieren würdest
Deal Velocity leidet, weil Vertrauen über Quellen entsteht und du nicht zitiert wirst.
Wann lohnt ein GEO Audit
Geeignet wenn, folgende Symptome bei euch auftauchen
Quick Qualification, damit du in 2 Minuten weißt, ob der Deep Dive für dich Sinn ergibt
Du wirst bei kaufnahen Fragen nicht genannt, obwohl du in deiner Branche relevant bist
Wettbewerber tauchen stabil in Shortlists auf, du wirst von KI-Antworten regelrecht ignoriert
LLMs beschreiben dein Angebot unklar, falsch oder widersprüchlich
Du hast Content, aber keine Compare/Alternatives-Coverage und keine zitierfähigen "Owned Sources"
Was beinhaltet das geo audit
Transparente Klarheit nach 4 Wochen
Du bekommst eine Baseline, Evidence und Prioritäten, die du intern, mit Partnern oder mit uns umsetzen kannst
Wo du genannt wirst (und wo du verlierst), pro Prompt-Cluster
Welche Quellen dominieren und warum deine Domain nicht zitiert wird
Welche Wettbewerber deine Shortlists besetzen (Competitor Delta)
Welche 10 Maßnahmen den größten Impact haben
Was ihr in 30/60/90 Tagen umsetzen solltet
Unser vorgehen
Wie funktioniert das Deep Dive GEO Audit?
Ein definierter Prozess mit klaren Outputs pro Woche, damit du jederzeit weißt, wo ihr steht.
Woche 1: Setup & Baseline
Wir definieren Prompt-Cluster und Wettbewerber-Set, bauen die Messgrundlage auf und erstellen die erste Baseline-Scorecard als Ausgangspunkt für alle weiteren Entscheidungen
Woche 2: Evidence & Ursachen
Wir dokumentieren, welche Anbieter genannt werden, welche Quellen zitiert werden und warum. Ergebnis ist eine evidence-basierte Ursachenliste: Entity-Signale, Quellenlage und Coverage-Gaps
Woche 3: Maßnahmen-Design
Wir übersetzen Findings in ein priorisiertes Maßnahmenpaket: welche Owned Assets (Citation Nodes, Compare/Alternatives) fehlen, welche Third-Party Citations sinnvoll sind und was zuerst umgesetzt werden sollte.
Woche 4 Final Report & Readout
Du erhältst einen finalen Report inklusive Scorecard, Citation Map und Competitor Delta sowie eine 30/60/90 Tage Roadmap mit Reihenfolge, Aufwand und Verantwortlichkeiten für Umsetzung oder unseren Blueprint
Case
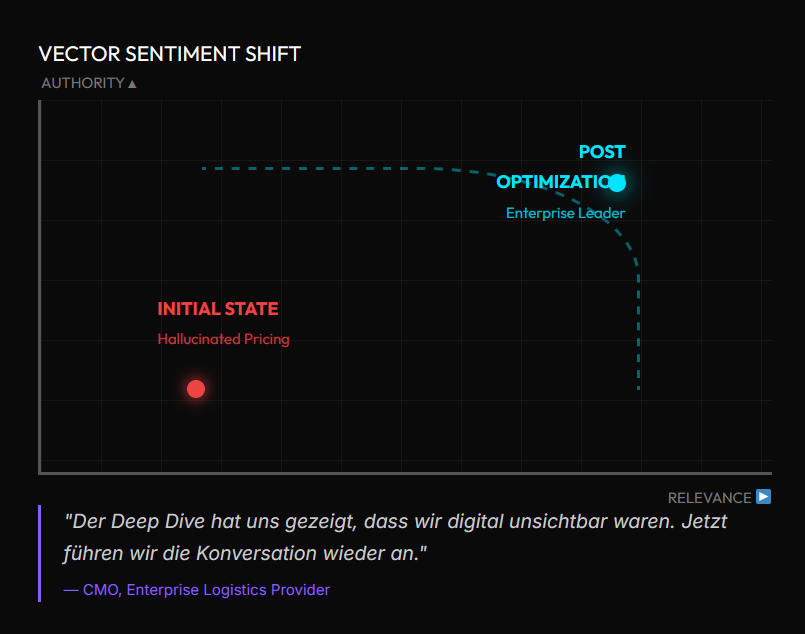
Von "Unsichtbar" zur Shortlist-Dominanz.
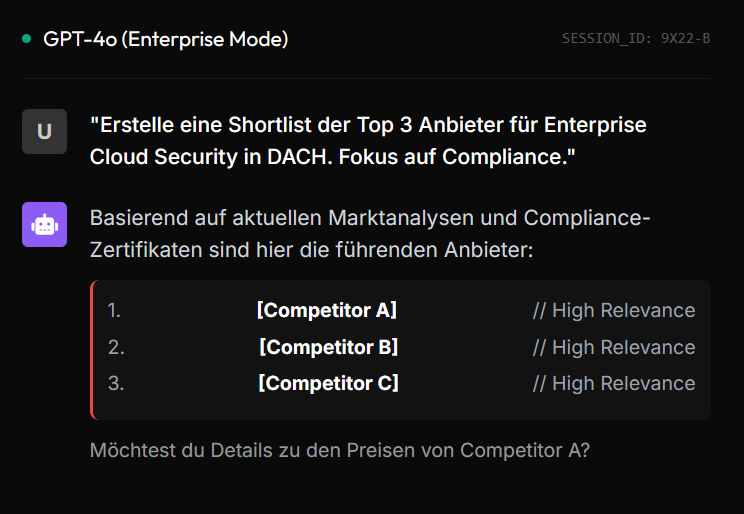
Das Problem: Ein führender Anbieter für Logistik-Software verlor Enterprise-Deals, obwohl er Marktführer war. Der Grund: ChatGPT behauptete fälschlicherweise, die Software sei „nur für KMUs geeignet“ (Pricing Halluzination).
Die Deep Dive Diagnose: Der Knowledge Graph war fragmentiert. Externe Quellen widersprachen sich. Die KI wählte den „sicheren Weg“ und empfahl den Wettbewerber.
Starte mit einem Quick GEO Audit
Du bist unsicher, wo deine Marke in KI-basierten Antworten auftaucht? Dann starte mit unseren unverbindlichen GEO Analyse und wir schauen uns gemeinsam an wo ihr genannt, zitiert und empfohlen werdet, oder ob LLMs euch noch komplett ignorieren.
GEO Analyse anfordern
FAQ: Häufige Fragen zu unserem GEO Audit
Was ist ein GEO Audit?
Ein 4-Wochen-Audit, das misst, ob und wie du in Answer Engines genannt, zitiert und empfohlen wirst. Du bekommst Scorecard, Ursachenanalyse und eine priorisierte Roadmap.
Worin unterscheidet sich das GEO Audit von einem SEO-Audit?
SEO optimiert Rankings und Klicks. GEO optimiert Nennung/Zitat/Empfehlung in generativen Antworten. Die Methodik umfasst zusätzlich Prompt-Cluster, Quellenanalyse, Entity-Klarheit und Re-Runs.
Welche Ergebnisse bekomme ich am Ende konkret?
Scorecard (SoA/SoC/SoM/Sentiment), Citation Map (Owned vs Third-Party), Competitor Delta (wer dominiert und warum), Evidence Findings sowie einen 30/60/90-Tage-Plan.
Wie misst ihr das, wenn es keinen „Traffic“ gibt?
Über definierte Prompt-Cluster (kaufnahe Intents) und wiederholte Re-Runs. So trennen wir echte Verbesserung von Schwankungen im Modell.
Welche Inputs braucht ihr von uns für das GEO Audit?
Domain/Produktseiten, Zielmärkte/Sprachen, 3–8 Wettbewerber, 1 Owner für Reviews. Optional: GSC/GA4 (hilft, ist nicht zwingend).
Wie viele Stakeholder müssen beteiligt sein?
Minimal: 1 Marketing/PMM Owner + 1 Person für Web/Content. Für schnellere Entscheidungen empfehlen wir einen kurzen Executive-Slot beim Final Readout.
Wie schnell sehen wir Verbesserungen?
Klarheit innerhalb von 4 Wochen. Sichtbare Verbesserungen folgen mit Umsetzung der Roadmap und werden über Re-Runs stabil gemessen.
Was passiert nach dem GEO Audit?
Entweder Blueprint (wir bauen die priorisierten Assets) oder Guard (Monitoring, Drift Alerts, Change Log). Welche Option sinnvoll ist, ergibt sich aus deiner Scorecard und den Findings.